目录
前言
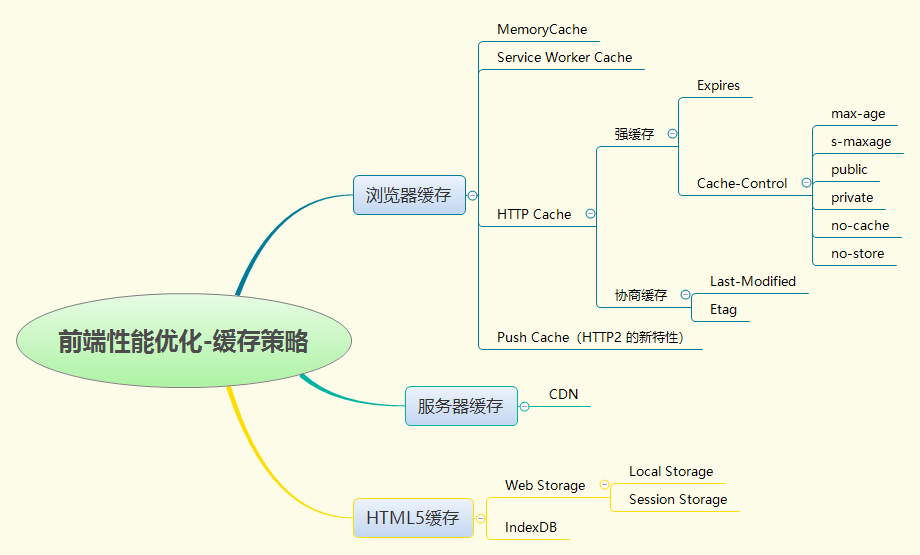
前端页面加载网络资源是必不可少的,因此前端性能的优化也就必须考虑到浏览器缓存。缓存可以说是性能优化中简单高效的一种优化方式了。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷。
Chrome 官方给出的解释:
通过网络获取内容既速度缓慢又开销巨大。较大的响应需要在客户端与服务器之间进行多次往返通信,
这会延迟浏览器获得和处理内容的时间,还会增加访问者的流量费用。因此,缓存并重复利用之前获取
的资源的能力成为性能优化的一个关键方面。
浏览器缓存机制
浏览器缓存机制有四个方面,它们按照获取资源时请求的优先级依次排列如下:
- Memory Cache
- Service Worker Cache
- HTTP Cache
- Push Cache(HTTP2 的新特性)
MemoryCache
介绍
MemoryCache 是指存在内存中的缓存(与之相对 disk cache 就是硬盘上的缓存)。从优先级上来说,它是浏览器最先尝试去命中的一种缓存。从效率上来说,它是响应速度最快的一种缓存。但是当进程结束后,也就是tab页关闭以后,内存里的数据也将不复存在。
那么哪些文件会被放入内存呢?
引用《前端性能优化原理与实践》说法
事实上,这个划分规则,一直以来是没有定论的。不过想想也可以理解,内存是有限的,很多时候需要先考虑即时呈现的内存余量,再根据具体的情况决定分配给内存和磁盘的资源量的比重——资源存放的位置具有一定的随机性。
虽然划分规则没有定论,但根据日常开发中观察的结果,包括我们开篇给大家展示的 Network 截图,我们至少可以总结出这样的规律:资源存不存内存,浏览器秉承的是“节约原则”。我们发现,Base64 格式的图片,几乎永远可以被塞进 memory cache,这可以视作浏览器为节省渲染开销的“自保行为”;此外,体积不大的 JS、CSS 文件,也有较大地被写入内存的几率——相比之下,较大的 JS、CSS 文件就没有这个待遇了,内存资源是有限的,它们往往被直接甩进磁盘。
Service Worker Cache
介绍
Service Worker 是一种独立于主线程之外的 Javascript 线程。Service Worker 能够操作的缓存是有别于浏览器内部的 memory cache 或者 disk cache 的。这个缓存是永久性的,即关闭 tab 或者浏览器,下次打开依然还在(而 memory cache 不是)。有两种情况会导致这个缓存中的资源被清除:手动调用 API cache.delete(resource) 或者容量超过限制,被浏览器全部清空。
Service Worker 的生命周期
Service Worker 的生命周期包括 install、active、working 三个阶段。
使用 Service Worker 实现离线缓存
注意: Server Worker 对协议是有要求的,必须以 https 协议为前提。
window.navigator.serviceWorker.register('/test.js').then(
function () {
console.log('注册成功')
}).catch(err => {
console.error("注册失败")
})
在 test.js 中,我们进行缓存的处理。假设我们需要缓存的文件分别是 test.html,test.css 和 test.js:
// Service Worker会监听 install事件,我们在其对应的回调里可以实现初始化的逻辑
self.addEventListener('install', event => {
event.waitUntil(
// 考虑到缓存也需要更新,open内传入的参数为缓存的版本号
caches.open('test-v1').then(cache => {
return cache.addAll([
// 此处传入指定的需缓存的文件名
'/test.html',
'/test.css',
'/test.js'
])
})
)
})
/**
Service Worker会监听所有的网络请求,网络请求的产生触发的是fetch事件,
我们可以在其对应的监听函数中实现对请求的拦截,
进而判断是否有对应到该请求的缓存,实现从Service Worker中取到缓存的目的
*/
self.addEventListener('fetch', event => {
event.respondWith(
// 尝试匹配该请求对应的缓存值
caches.match(event.request).then(res => {
// 如果匹配到了,调用Server Worker缓存
if (res) {
return res;
}
// 如果没匹配到,向服务端发起这个资源请求
return fetch(event.request).then(response => {
if (!response || response.status !== 200) {
return response;
}
// 请求成功的话,将请求缓存起来。
caches.open('test-v1').then(function(cache) {
cache.put(event.request, response);
});
return response.clone();
});
})
);
});
HTTP Cache
HTTP 缓存是开发中最用的最多的,也是比较熟悉的缓存机制,它又分为强缓存和协商缓存。优先级较高的是强缓存,在命中强缓存失败的情况下,才会走协商缓存。
强缓存
强缓存是利用 http 头中的 Expires 和 Cache-Control 两个字段来控制的。
强缓存的实现
- expires
- Cache-Control 通过expires和Cache-Control设置缓存时间戳。
注意:
- expires 是个时间戳。向服务器请求资源时,浏览器会对比本地时间和expires时间戳,只有本地时间小于expires设定的时间,才会直接从缓冲中读取,因此本地时间有误的话,expires将无法达到预期效果。
- expires 有局限性,HTTP1.1新增Cache-Control。expires 能做的事情,Cache-Control 都能做;expires 完成不了的事情,Cache-Control 也能做。因此,Cache-Control 可以视作是 expires 的完全替代方案。在当下的前端实践里,我们继续使用 expires 的唯一目的就是向下兼容。
设置Cache-Control
// 该资源在 51532000 秒以内都是有效的,完美地规避了时间戳带来的潜在问题。
cache-control: max-age=51532000
Cache-Control 相对于 expires 更加准确,它的优先级也更高。当 Cache-Control 与 expires 同时出现时,我们以 Cache-Control 为准。
扩展: s-maxage
cache-control: max-age=3600, s-maxage=31536000
s-maxage 优先级高于 max-age,两者同时出现时,优先考虑 s-maxage。如果 s-maxage 未过期,则向代理服务器请求其缓存内容。s-maxage仅在代理服务器中生效,客户端中我们只考虑max-age。
public 与 private
public 与 private 是针对资源是否能够被代理服务缓存而存在的一组对立概念。
- 为资源设置了 public,那么它既可以被浏览器缓存,也可以被代理服务器缓存。
- 为资源设置了 private, 则该资源只能被浏览器缓存。private 为默认值。
no-store 与 no-cache
- 为资源设置了 no-cache,每一次发起请求都不会再去询问浏览器的缓存情况,而是直接向服务端去确认该资源是否过期
- 为资源设置了 no-store,请求不会考虑任何的缓存,直接向服务端发送请求、并下载完整的响应。
协商缓存
协商缓存依赖于浏览器与服务端之间的通信。
协商缓存机制下,浏览器需要向服务器去询问缓存的相关信息,进而判断是重新发起请求、下载完整的响应,还是从本地获取缓存的资源。
如果服务端提示缓存资源未改动(Not Modified),资源会被重定向到浏览器缓存,这种情况下网络请求对应的状态码是 304
协商缓存的实现
- Last-Modified
- Etag
Last-Modified
Last-Modified 是一个时间戳,如果我们启用了协商缓存,它会在首次请求时随着 Response Headers 返回:
Last-Modified: Fri, 27 Oct 2017 06:35:57 GMT
随后我们每次请求时,会带上一个叫 If-Modified-Since 的时间戳字段,它的值正是上一次 response 返回给它的 last-modified 值:
If-Modified-Since: Fri, 27 Oct 2017 06:35:57 GMT
服务器接收到这个时间戳后,会比对该时间戳和资源在服务器上的最后修改时间是否一致,从而判断资源是否发生了变化。如果发生了变化,就会返回一个完整的响应内容,并在 Response Headers 中添加新的 Last-Modified 值;否则,返回如上图的 304 响应,Response Headers 不会再添加 Last-Modified 字段。
弊端:
-
我们编辑了文件,但文件的内容没有改变。服务端并不清楚我们是否真正改变了文件,它仍然通过最后编辑时间进行判断。因此这个资源在再次被请求时,会被当做新资源,进而引发一次完整的响应——不该重新请求的时候,也会重新请求。
-
当我们修改文件的速度过快时(比如花了 100ms 完成了改动),由于 If-Modified-Since 只能检查到以秒为最小计量单位的时间差,所以它是感知不到这个改动的——该重新请求的时候,反而没有重新请求了
这两个场景其实指向了同一个 bug——服务器并没有正确感知文件的变化。为了解决这样的问题,Etag 作为 Last-Modified 的补充出现了。
Etag
Etag 和 Last-Modified 类似,当首次请求时,我们会在响应头里获取到一个最初的标识符字符串,举个例子,它可以是这样的:
ETag: W/"2a3b-1602480f459"
那么下一次请求时,请求头里就会带上一个值相同的、名为 if-None-Match 的字符串供服务端比对了:
If-None-Match: W/"2a3b-1602480f459"
Etag 的生成过程需要服务器额外付出开销,会影响服务端的性能,这是它的弊端。因此启用 Etag 需要我们审时度势。正如我们刚刚所提到的——Etag 并不能替代 Last-Modified,它只能作为 Last-Modified 的补充和强化存在。 Etag 在感知文件变化上比 Last-Modified 更加准确,优先级也更高。当 Etag 和 Last-Modified 同时存在时,以 Etag 为准。
HTTP 缓存决策指南
面对具体的缓存需求的解决方案, 如下图:
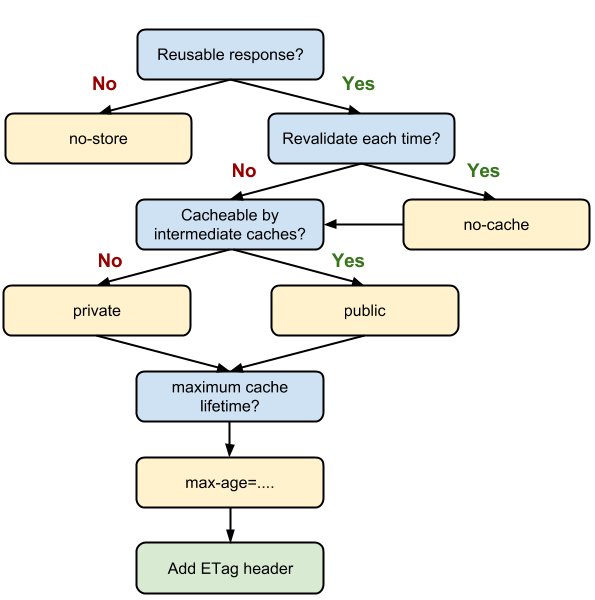
当我们的资源内容不可复用时,直接为 Cache-Control 设置 no-store,拒绝一切形式的缓存;否则考虑是否每次都需要向服务器进行缓存有效确认,如果需要,那么设 Cache-Control 的值为 no-cache;否则考虑该资源是否可以被代理服务器缓存,根据其结果决定是设置为 private 还是 public;然后考虑该资源的过期时间,设置对应的 max-age 和 s-maxage 值;最后,配置协商缓存需要用到的 Etag、Last-Modified 等参数。
Push Cache
Push Cache 是指 HTTP2 在 server push 阶段存在的缓存。
- Push Cache 是缓存的最后一道防线。浏览器只有在 Memory Cache、HTTP Cache 和 Service Worker Cache 均未命中的情况下才会去询问 Push Cache。
- Push Cache 是一种存在于会话阶段的缓存,当 session 终止时,缓存也随之释放。
- 不同的页面只要共享了同一个 HTTP2 连接,那么它们就可以共享同一个 Push Cache。
服务器缓存CDN
CDN含义
CDN (Content Delivery Network,即内容分发网络)指的是一组分布在各个地区的服务器。
这些服务器存储着数据的副本,因此服务器可以根据哪些服务器与用户距离最近,来满足数据的请求。
CDN 提供快速服务,较少受高流量影响。
CDN的核心功能特写
核心点:
- 缓存–就是说我们把资源 copy 一份到 CDN 服务器上这个过程
- 回源–就是说 CDN 发现自己没有这个资源(一般是缓存的数据过期了),转头向根服务器(或者它的上层服务器)去要这个资源的过程。
CDN作用
- 存放静态资源,减少项目资源的体积
- 提升请求的响应速度,节省响应时间
- CDN 服务器的域名与项目域名分开,同一个域名下的请求会不分青红皂白地携带 Cookie,而静态资源往往并不需要 Cookie 携带什么认证信息。把静态资源和主页面置于不同的域名下,完美地避免了不必要的 Cookie 的出现!
HTML5缓存
- Cookie (不是H5新增)
- Local Storage
- Session Storage
- IndexedDB
说到H5缓存 Local Storage和Session Storage就不可避免的说到Cookie,三者经常在一起进行比较,本文也不脱俗,也将三者放在一起比较。
三者作用
- Cookie的作用是与服务器进行交互
- Storage为了在本地存储数据而生
三者区别
| 类别 | 生命周期 | 存放数据大小 | 作用域 | 与服务器通信 |
|---|---|---|---|---|
| Cookie | 可设置生命周期,不设置关闭浏览器窗口,cookie就消失了 | 4KB | 遵循同源策略 | 参与服务器通信 |
| Local Storage | Local Storage 是持久化的本地存储,存储在其中的数据是永远不会过期的,使其消失的唯一办法是手动删除 | 5-10M | 遵循同源策略 | 不参与 |
| Session Storage | 而 Session Storage 是临时性的本地存储,它是会话级别的存储,当会话结束(页面被关闭)时,存储内容也随之被释放 | 5-10M | 遵循同源策略 Session Storage 特别的一点在于,即便是相同域名下的两个页面,只要它们不在同一个浏览器窗口中打开,那么它们的 Session Storage 内容便无法共享。 | 不参与 |
三者的关系
HTTP 协议是一个无状态协议,服务器接收客户端的请求,返回一个响应,通信到此就结束了,而Cookie 的本职工作并非本地存储,而是“维持状态”。Cookie就是一个存储在浏览器里的一个小小的文本文件,同一个域名下的所有请求,都会携带 Cookie。它携带用户信息附着在 HTTP 请求上,在浏览器和服务器之间通信。当服务器检查 Cookie 的时候,便可以获取到客户端的状态。随着前端应用复杂度的提高,Cookie 也渐渐演化为了一个“存储多面手”——它不仅仅被用于维持状态,还被塞入了一些乱七八糟的其它信息,被迫承担起了本地存储的“重任”。为了弥补 Cookie 的局限性,让“专业的人做专业的事情”,Web Storage 出现了。
三者应用场景
Cookie
(1)判断用户是否登录过网站,以便下次登录时能够实现自动登录(或者记住密码)。 (2)保存上次登录的事件等信息。 (3)保存上次查看的页面 (4)浏览计数
Local Storage
(1)Local Storage 的特点之一是持久存储一些内容稳定的资源,如CSS、JS等静态资源 (2)存储登录成功的token值,请求携带token与后端校验
Session Storage
(1)更适合用来存储生命周期和它同步的会话级别的信息。比如微博的 Session Storage 就主要是存储你本次会话的浏览足迹。
具体的应用场景需要根据具体的业务去选择,可以从三个以下方面去考虑:
- 是否与服务器通信
- 存储的大小
- 存储周期
IndexedDB
IndexedDB 是一个运行在浏览器上的非关系型数据库。IndexedDB 是没有存储上限的(一般来说不会小于 250M)。它不仅可以存储字符串,还可以存储二进制数据。IndexedDB的作用就是在本地创建一个数据库,存储大量数据,可存储、添加、修改、删除数据等。
通过一个基本的 IndexedDB 使用流程,旨在对 IndexedDB 形成一个感性的认知:
- 打开/创建一个 IndexedDB 数据库(当该数据库不存在时,open 方法会直接创建一个名为 xiaoceDB 新数据库)。
// 后面的回调中,我们可以通过event.target.result拿到数据库实例
let db
// 参数1位数据库名,参数2为版本号
const request = window.indexedDB.open("xiaoceDB", 1)
// 使用IndexedDB失败时的监听函数
request.onerror = function(event) {
console.log('无法使用IndexedDB')
}
// 成功
request.onsuccess = function(event){
// 此处就可以获取到db实例
db = event.target.result
console.log("你打开了IndexedDB")
}
- 创建一个 object store(object store 对标到数据库中的“表”单位)。
// onupgradeneeded事件会在初始化数据库/版本发生更新时被调用,我们在它的监听函数中创建object store
request.onupgradeneeded = function(event){
let objectStore
// 如果同名表未被创建过,则新建test表
if (!db.objectStoreNames.contains('test')) {
objectStore = db.createObjectStore('test', { keyPath: 'id' })
}
}
- 构建一个事务来执行一些数据库操作,像增加或提取数据等。
// 创建事务,指定表格名称和读写权限
const transaction = db.transaction(["test"],"readwrite")
// 拿到Object Store对象
const objectStore = transaction.objectStore("test")
// 向表格写入数据
objectStore.add({id: 1, name: 'xiuyan'})
- 通过监听正确类型的事件以等待操作完成。
// 操作成功时的监听函数
transaction.oncomplete = function(event) {
console.log("操作成功")
}
// 操作失败时的监听函数
transaction.onerror = function(event) {
console.log("这里有一个Error")
}
应用场景
当我们需要存储大量数据,并需要对这些数据进行一些操作时,使用IndexedDB是非常有必要的。
小结
前端性能优化专题,只是提供前端优化的方向,对每篇文章的知识点,不过多的累赘,点到为止。这个专题的目的旨在:当你需要进行前端性能优化时,可以想到从哪些方面进行优化?
参考文章:
首屏渲染体验和 SEO 的优化方案